
There is no equivalent to the SSIS Lookup transformation in T-SQL – but there is a workaround if you’re careful.
The big issue that you face is about the number of rows that you connect to in the Lookup. SQL Books Online (BOL) says:
- If there is no matching entry in the reference dataset, no join occurs. By default, the Lookup transformation treats rows without matching entries as errors. However, you can configure the Lookup transformation to redirect such rows to a no match output. For more information, see Lookup Transformation Editor (General Page) and Lookup Transformation Editor (Error Output Page).
- If there are multiple matches in the reference table, the Lookup transformation returns only the first match returned by the lookup query. If multiple matches are found, the Lookup transformation generates an error or warning only when the transformation has been configured to load all the reference dataset into the cache. In this case, the Lookup transformation generates a warning when the transformation detects multiple matches as the transformation fills the cache.
This is very important. It means that every row that enters the Lookup transformation comes out. This could be coming out of the transformation as an error, or through a ‘No Match’ output, with an ignored failure, or having found a row. But it will never return multiple copies of the row, even if it has matched two rows. This last point is inherently different to what happens in T-SQL. In T-SQL, any time you do a join, whether an INNER JOIN or an OUTER JOIN, if you match multiple rows on the right hand side, you get two copies of the row from the left. When doing Lookups in the world of ETL (as you would with SSIS), this is a VeryBadThing.

You see, there’s an assumption with ETL systems that things are under control in your data warehouse. It’s this assumption that I want to look at in this post. I do actually think it’s quite a reasonable one, but I also recognise that a lot of people don’t feel that it’s something they can rely on. Either way, I’ll show you a couple of ways that you can implement some workarounds, and it also qualifies this post for this month’s T-SQL Tuesday, hosted by Dev Nambi.
Consider that you have a fact row, and you need to do a lookup into a dimension table to find the appropriate key value (I might know that the fact row corresponds to the Adelaide office, but having moved recently, I would want to know whether it’s the new version of the office or the old one). I know that ‘ADL’ is unique in my source system – quite probably because of a unique constraint in my OLTP environment – but I don’t have that guarantee in my warehouse. Actually, I know that I will have multiple rows for ADL. Only one is current at any point in time, but can I be sure that if I try to find the ADL record for a particular point in time, I will only find one row?
A typical method for versioning dimension records (a Type 2 scenario) is to have a StartDate and EndDate for each version. But implementing logic to make sure there can never be an overlap is tricky. It’s easy enough to test, particularly since LAG/LEAD functions became available, but putting an actual constraint in there is harder – even more so if you’re dealing with something like Microsoft’s Parallel Data Warehouse, which doesn’t support unique constraints (this is totally fair enough, when you consider that the rows for a single table can be spread across hundreds of sub-tables).
If we know that we have contiguous StartDate/EndDate ranges, with no gaps and no overlaps, then we can confidently write a query like:
|
1 2 3 4 5 |
FROM facttable f LEFT JOIN dimtable d ON d.BusinessKey = f.DimBK AND d.StartDate <= f.FactDate AND f.FactDate < d.EndDate |
By doing a LEFT JOIN, we know that we’re never going to eliminate a fact by failing to match it (and can introduce an inferred dimension member), but if we have somehow managed to have overlapping records, then we could inadvertently get a second copy of our fact row. That’s going to wreck our aggregates, and the business will lose faith in the environment that has been put in.
Of course, your dimension management is sound. You will never have this problem. Really. But what happens if someone has broken the rules and manually tweaked something? What if there is disagreement amongst BI developers about the logic that should be used for EndDate values (some prefer to have a gap of a day, as in “Jan 1 to Jan 31, Feb 1 to Feb 28”, whereas others prefer to have the EndDate value the same as the next StartDate. There’s definitely potential for inconsistency between developers.
Whatever the reason, if you suddenly find yourself with the potential for two rows to be returned by a ‘lookup join’ like this, you have a problem. Clearly the SSIS Lookup transform ensures that there is never a second row considered to match, but T-SQL doesn’t offer a join like that.
But it does give us APPLY.
We can use APPLY to reproduce the same functionality as a join, by using code such as:
|
1 2 3 4 5 |
FROM facttable f OUTER APPLY (SELECT * FROM dimtable d WHERE d.BusinessKey = f.DimBK AND d.StartDate <= f.FactDate AND f.FactDate < d.EndDate) d1 |
But because we now have a fully-fledged correlated table expression, we can be a little more tricky, and tweak it with TOP,
|
1 2 3 4 5 6 |
FROM facttable f OUTER APPLY (SELECT TOP (1) * FROM dimtable d WHERE d.BusinessKey = f.DimBK AND d.StartDate <= f.FactDate AND f.FactDate < d.EndDate) d1 |
, which leaves us being confident that the number of rows in the set produced by our FROM clause is exactly the same number as we have in our fact table. The OUTER APPLY (rather than CROSS APPLY) makes sure we have lose rows, and the TOP (1) ensures that we never match more than one.
But still I feel like we have a better option that having to consider which method of StartDate/EndDate logic is used.
What we want is the most recent version of the dimension member at the time of the fact record. To me, this sounds like a TOP query with an ORDER BY and a filter,
|
1 2 3 4 5 6 |
FROM facttable f OUTER APPLY (SELECT TOP (1) * FROM dimtable d WHERE d.BusinessKey = f.DimBK AND d.StartDate <= f.FactDate ORDER BY d.StartDate DESC) d1 |
, and you will notice that I’m no longer using the EndDate at all. In fact, I don’t need to bother having it in the table at all.
Now, the worst scenario that I can imagine is that I have a fact record that has been backdated to before the dimension member appeared in the system. I’m sure you can imagine it, such as when someone books vacation time before they’ve actually started with a company. The dimension member StartDate might be populated with when they actually start with the company, but they have activity before their record becomes ‘current’.
Well, I solve that with a second APPLY.
|
1 2 3 4 5 6 7 8 9 10 11 |
FROM facttable f OUTER APPLY (SELECT TOP (1) * FROM dimtable d WHERE d.BusinessKey = f.DimBK AND d.StartDate <= f.FactDate ORDER BY d.StartDate DESC) d1 OUTER APPLY (SELECT TOP (1) * FROM dimtable d WHERE d1.BusinessKey IS NULL AND d.BusinessKey = f.DimBK ORDER BY d.StartDate ASC) d1a |
Notice that I correlate the second APPLY to the first one, with the predicate “d1.BusinessKey IS NULL”. This is very important, and addresses a common misconception, as many people will look at this query and assume that the second APPLY will be executed for every row. Let’s look at the plan that would come about here.
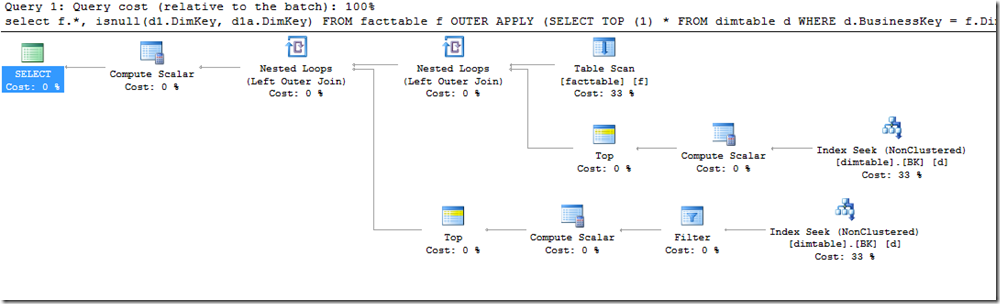
I don’t have any indexes on facttable – I’m happy enough to scan the whole table, but I want you to notice the two Nested Loop operators and the lower branches for them. A Nested Loop operator sucks data from it’s top branch, and for every row that comes in, requests any matching rows from the lower one.
We already established that the APPLY with TOP is not going to change the number of rows, so the number of rows that the left-most Nested Loop is pulling from its top branch is the same as the one on its right, which also matches the rows from the Table Scan. And we know that we do want to check dimtable for every row that’s coming from facttable.
But we don’t want to be doing a Seek in dimtable a second time for every row that the Nested Loop pulls from factable.
Luckily, that’s another poor assumption. People misread this about execution plans all the time.
When taught how to read an execution plan, many will head straight to the top-right, and whenever they hit a join operator, head to the right of that branch. And it’s true that the data streams do start there. It’s not the full story though, and it’s shown quite clearly here, through that Filter operator.
That Filter operator is no ordinary one, but has a Startup Expression Predicate property.
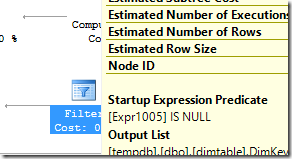
This means that the operator only requests rows from its right, if that predicate is satisfied. In this case, it means if it didn’t find matching row the first time it looked in dimtable. Therefore, the second Index Seek won’t get executed except in very rare situations. And we know (but the QO doesn’t) that it will be typically none at all, and that the estimated cost is not going to be 33%, but much more like 0%.
So now you have a way of being able to do lookups that will not only guarantee that one row (at most) will be picked up, but you also have a pattern that will let you do a second lookup for those times when you don’t have the first.
And keep your eye out for Startup Expression Predicates – they can be very useful for knowing which parts of your execution plan don’t need to get executed…




This Post Has 6 Comments
Hi,
I had below doubt on second outer apply
When there is condition d1.BusinessKey IS NULL
How can this cindition execute "AND d.BusinessKey = f.DimBK "
Thanks,
Surjit
Hi Surjit,
The first predicate is on the set d1, which is reflected in the Startup Filter. It means it only does this lookup if the first one (d1) has failed to find something.
The second predicate is on the tables d and f, and is used to find the record in the dimension table.
Does this help?
Rob
Hi Rob,
your post helped me a hell lot. I was trying to solve a similar scenario where I wanted to build a parent child table structure and I only knew that the parent is the next of the preceding elements in the list with HierarchyLevel-1. By changing the join that I made first your APPLY statement and constraining my resultset to TOP 1 DESC, I obtained exactly my desired result. Otherwise, by use of a common join I would have gotten as much duplicate rows as much rows of lower level were found in the list before.
Thanks a lot!
Best regards,
Tarek
That’s great, Tarek! 🙂
Pingback: What were you thinking, Rob? - LobsterPot Blogs
Pingback: SQL Community time capsule - LobsterPot Blogs