
This is a white paper that I put together recently about APS / PDW Query Optimisation. You may have seen it at http://blogs.technet.com/b/dataplatforminsider/archive/2014/11/14/aps-best-practice-how-to-optimize-query-performance-by-minimizing-data-movement.aspx as well, but in case you haven’t, read on!
I think the significance of this paper is big, because most people who deal with data warehouses (and PDW even more so) haven’t spent much time thinking about Query Optimisation techniques, and certainly not about how they can leverage features of SQL Server’s Query Optimizer to minimise data movement (which is probably the largest culprit for poor performance in a PDW environment).
Oh, and I have another one that I’m writing too…
The Analytics Platform System, with its MPP SQL Server engine (SQL Server Parallel Data Warehouse) can deliver performance and scalability for analytics workloads that you may not have expected from SQL Server. But there are key differences in working with SQL Server PDW and SQL Server Enterprise Edition that one should be aware of in order to take full advantage of the SQL Server PDW capabilities. One of the most important considerations when tuning queries in Microsoft SQL Server Parallel Data Warehouse is the minimisation of data movement. This post shows a useful technique regarding the identification of redundant joins through additional predicates that simulate check constraints.
Microsoft’s PDW, part of the Analytics Platform System (APS), offers scale-out technology for data warehouses. This involves spreading data across a number of SQL Server nodes and distributions, such that systems can host up to many petabytes of data. To achieve this, queries which use data from multiple distributions to satisfy joins must leverage the Data Movement Service (DMS) to relocate data during the execution of the query. This data movement is both a blessing and a curse; a blessing because it is the fundamental technology which allows the scale-out features to work, and a curse because it can be one of the most expensive parts of query execution. Furthermore, tuning to avoid data movement is something which many SQL Server query tuning experts have little experience, as it is unique to the Parallel Data Warehouse edition of SQL Server.
Regardless of whether data in PDW is stored in a column-store or row-store manner, or whether it is partitioned or not, there is a decision to be made as to whether a table is to be replicated or distributed. Replicated tables store a full copy of their data on each compute node of the system, while distributed tables distribute their data across distributions, of which there are eight on each compute node. In a system with six compute nodes, there would be forty-eight distributions, with an average of less than 2.1% (100% / 48) of the data in each distribution.
When deciding whether to distribute or replicate data, there are a number of considerations to bear in mind. Replicated data uses more storage and also has a larger management overhead, but can be more easily joined to data, as every SQL node has local access to replicated data. By distributing larger tables according to the hash of one of the table columns (known as the distribution key), the overhead of both reading and writing data is reduced – effectively reducing the size of databases by an order of magnitude.
Having decided to distribute data, choosing which column to use as the distribution key is driven by factors including the minimisation of data movement and the reduction of skew. Skew is important because if a distribution has much more than the average amount of data, this can affect query time. However, the minimisation of data movement is probably the most significant factor in distribution-key choice.
Joining two tables together involves identifying whether rows from each table match to according a number of predicates, but to do this, the two rows must be available on the same compute node. If one of the tables is replicated, this requirement is already satisfied (although it might need to be ‘trimmed’ to enable a left join), but if both tables are distributed, then the data is only known to be on the same node if one of the join predicates is an equality predicate between the distribution keys of the tables, and the data types of those keys are exactly identical (including nullability and length). More can be read about this in the excellent whitepaper about Query Execution in Parallel Data Warehouse at http://gsl.azurewebsites.net/Portals/0/Users/Projects/pdwau3/sigmod2012.pdf
To avoid data movement between commonly-performed joins, creativity is often needed by the data warehouse designers. This could involve the addition of extra columns to tables, such as adding the CustomerKey to many fact data tables (and using this as the distribution key), as joins between orders, items, payments, and other information required for a given report, as all these items are ultimately about a customer, and adding additional predicates to each join to alert the PDW Engine that only rows within the same distribution could possibly match. This is thinking that is alien for most data warehouse designers, who would typically feel that adding CustomerKey to a table not directly related to a Customer dimension is against best-practice advice.
Another technique commonly used by PDW data warehouse designers that is rarely seen in other SQL Server data warehouses is splitting tables up into two, either vertically or horizontally, whereas both are relatively common in PDW to avoid some of the problems that can often occur.
Splitting a table vertically is frequently done to reduce the impact of skew when the ideal distribution key for joins is not evenly distributed. Imagine the scenario of identifiable customers and unidentifiable customers, as increasingly the situation as stores have loyalty programs allowing them to identify a large portion (but not all) customers. For the analysis of shopping trends, it could be very useful to have data distributed by customer, but if half the customers are unknown, there will be a large amount of skew.
To solve this, sales could be split into two tables, such as Sales_KnownCustomer (distributed by CustomerKey) and Sales_UnknownCustomer (distributed by some other column). When analysing by customer, the table Sales_KnownCustomer could be used, including the CustomerKey as an additional (even if redundant) join predicate. A view performing a UNION ALL over the two tables could be used to allow reports that need to consider all Sales.
The query overhead of having the two tables is potentially high, especially if we consider tables for Sales, SaleItems, Deliveries, and more, which might all need to be split into two to avoid skew while minimising data movement, using CustomerKey as the distribution key when known to allow customer-based analysis, and SalesKey when the customer is unknown.
By distributing on a common key the impact is to effectively create mini-databases which are split out according to groups of customers, with all of the data about a particular customer residing in a single database. This is similar to the way that people scale out when doing so manually, rather than using a system such as PDW. Of course, there is a lot of additional overhead when trying to scale out manually, such as working out how to execute queries that do involve some amount of data movement.
By splitting up the tables into ones for known and unknown customers, queries that were looking something like the following:
|
1 2 3 4 5 |
SELECT … FROM Sales AS s JOIN SaleItems AS si ON si.SalesKey = s.SalesKey JOIN Delivery_SaleItems AS dsi ON dsi.LineItemKey = si.LineItemKey JOIN Deliveries AS d ON d.DeliveryKey = dsi.DeliveryKey |
…would become something like:
|
1 |
|
1 2 3 4 5 |
SELECT … FROM Sales_KnownCustomer AS s JOIN SaleItems_KnownCustomer AS si ON si.SalesKey = s.SalesKey AND si.CustomerKey = s.CustomerKey JOIN Delivery_SaleItems_KnownCustomer AS dsi ON dsi.LineItemKey = si.LineItemKey AND dsi.CustomerKey = s.CustomerKey JOIN Deliveries_KnownCustomer AS d ON d.DeliveryKey = dsi.DeliveryKey AND d.CustomerKey = s.CustomerKey UNION ALL SELECT … FROM Sales_UnknownCustomer AS s JOIN SaleItems_UnknownCustomer AS li ON si.SalesKey = s.SalesKey JOIN Delivery_SaleItems_UnknownCustomer AS dsi ON dsi.LineItemKey = s.LineItemKey AND dsi.SalesKey = s.SalesKey JOIN Deliveries_UnknownCustomer AS d ON d.DeliveryKey = s.DeliveryKey AND d.SalesKey = s.SalesKey |
I’m sure you can appreciate that this becomes a much larger effort for query writers, and the existence of views to simplify querying back to the earlier shape could be useful. If both CustomerKey and SalesKey were being used as distribution keys, then joins between the views would require both, but this can be incorporated into logical layers such as Data Source Views much more easily than using UNION ALL across the results of many joins. A DSV or Data Model could easily define relationships between tables using multiple columns so that self-serving reporting environments leverage the additional predicates.
The use of views should be considered very carefully, as it is easily possible to end up with views that nest views that nest view that nest views, and an environment that is very hard to troubleshoot and performs poorly. With sufficient care and expertise, however, there are some advantages to be had.
The resultant query would look something like:
|
1 |
SELECT … FROM Sales AS s JOIN SaleItems AS li ON si.SalesKey = s.SalesKey AND si.CustomerKey = s.CustomerKey JOIN Delivery_SaleItems AS dsi ON dsi.LineItemKey = si.LineItemKey AND dsi.CustomerKey = s.CustomerKey AND dsi.SalesKey = s.SalesKey JOIN Deliveries AS d ON d.DeliveryKey = dsi.DeliveryKey AND d.CustomerKey = s.CustomerKey AND d.SalesKey = s.SalesKey |
Joining multiple sets of tables which have been combined using UNION ALL is not the same as performing a UNION ALL of sets of tables which have been joined. Much like any high school mathematics teacher will happily explain that (a*b)+(c*d) is not the same as (a+c)*(b+d), additional combinations need to be considered when the logical order of joins and UNION ALLs.

Notice that when we have (TableA1 UNION ALL TableA2) JOIN (TableB1 UNION ALL TableB2), we must perform joins not only between TableA1 and TableB1, and TableA2 and TableB2, but also TableA1 and TableB2, and TableB1 and TableA2. These last two combinations do not involve tables with common distribution keys, and therefore we would see data movement. This is despite the fact that we know that there can be no matching rows in those combinations, because some are for KnownCustomers and the others are for UnknownCustomers. Effectively, the relationships between the tables would be more like the following diagram:
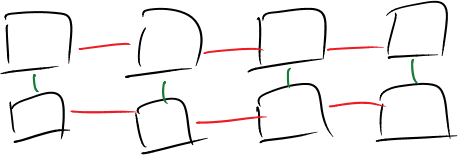
There is an important stage of Query Optimization which must be considered here, and which can be leveraged to remove the need for data movement when this pattern is applied – that of Contradiction.
The contradiction algorithm is an incredibly useful but underappreciated stage of Query Optimization. Typically it is explained using an obvious contradiction such as WHERE 1=2. Notice the effect on the query plans of using this predicate.
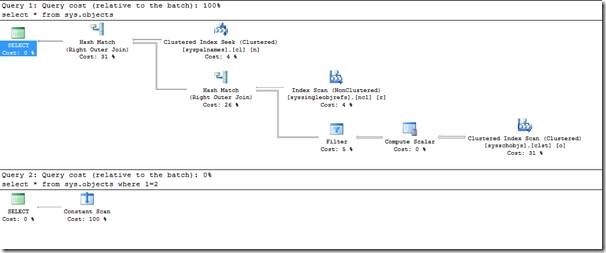
Because the Query Optimizer recognises that no rows can possibly satisfy the predicate WHERE 1=2, it does not access the data structures seen in the first query plan.
This is useful, but many readers may not consider queries that use such an obvious contradiction are going to appear in their code.
But suppose the views that perform a UNION ALL are expressed in this form:
|
1 2 3 4 |
CREATE VIEW dbo.Sales AS SELECT * FROM dbo.Sales_KnownCustomer WHERE CustomerID > 0 UNION ALL SELECT * FROM dbo.Sales_UnknownCustomer WHERE CustomerID = 0; |
Now, we see a different kind of behaviour.
Before the predicates are used, the query on the views is rewritten as follows (with SELECT clauses replaced by ellipses).
|
1 |
SELECT … FROM (SELECT … FROM (SELECT ... FROM [sample_vsplit].[dbo].[Sales_KnownCustomer] AS T4_1 UNION ALL SELECT … FROM [tempdb].[dbo].[TEMP_ID_4208] AS T4_1) AS T2_1 INNER JOIN (SELECT … FROM (SELECT … FROM [sample_vsplit].[dbo].[SaleItems_KnownCustomer] AS T5_1 UNION ALL SELECT … FROM [tempdb].[dbo].[TEMP_ID_4209] AS T5_1) AS T3_1 INNER JOIN (SELECT … FROM (SELECT … FROM [sample_vsplit].[dbo].[Delivery_SaleItems_KnownCustomer] AS T6_1 UNION ALL SELECT … FROM [tempdb].[dbo].[TEMP_ID_4210] AS T6_1) AS T4_1 INNER JOIN (SELECT … FROM [sample_vsplit].[dbo].[Deliveries_KnownCustomer] AS T6_1 UNION ALL SELECT … FROM [tempdb].[dbo].[TEMP_ID_4211] AS T6_1) AS T4_2 ON (([T4_2].[CustomerKey] = [T4_1].[CustomerKey]) AND ([T4_2].[SalesKey] = [T4_1].[SalesKey]) AND ([T4_2].[DeliveryKey] = [T4_1].[DeliveryKey]))) AS T3_2 ON (([T3_1].[CustomerKey] = [T3_2].[CustomerKey]) AND ([T3_1].[SalesKey] = [T3_2].[SalesKey]) AND ([T3_2].[SaleItemKey] = [T3_1].[SaleItemKey]))) AS T2_2 ON (([T2_2].[CustomerKey] = [T2_1].[CustomerKey]) AND ([T2_2].[SalesKey] = [T2_1].[SalesKey]))) AS T1_1 |
Whereas with the inclusion of the additional predicates, the query simplifies to:
|
1 |
SELECT … FROM (SELECT … FROM (SELECT … FROM [sample_vsplit].[dbo].[Sales_KnownCustomer] AS T4_1 WHERE ([T4_1].[CustomerKey] > 0)) AS T3_1 INNER JOIN (SELECT … FROM (SELECT … FROM [sample_vsplit].[dbo].[SaleItems_KnownCustomer] AS T5_1 WHERE ([T5_1].[CustomerKey] > 0)) AS T4_1 INNER JOIN (SELECT … FROM (SELECT … FROM [sample_vsplit].[dbo].[Delivery_SaleItems_KnownCustomer] AS T6_1 WHERE ([T6_1].[CustomerKey] > 0)) AS T5_1 INNER JOIN (SELECT … FROM [sample_vsplit].[dbo].[Deliveries_KnownCustomer] AS T6_1 WHERE ([T6_1].[CustomerKey] > 0)) AS T5_2 ON (([T5_2].[CustomerKey] = [T5_1].[CustomerKey]) AND ([T5_2].[SalesKey] = [T5_1].[SalesKey]) AND ([T5_2].[DeliveryKey] = [T5_1].[DeliveryKey]))) AS T4_2 ON (([T4_1].[CustomerKey] = [T4_2].[CustomerKey]) AND ([T4_1].[SalesKey] = [T4_2].[SalesKey]) AND ([T4_2].[SaleItemKey] = [T4_1].[SaleItemKey]))) AS T3_2 ON (([T3_2].[CustomerKey] = [T3_1].[CustomerKey]) AND ([T3_2].[SalesKey] = [T3_1].[SalesKey])) UNION ALL SELECT … FROM (SELECT … FROM [sample_vsplit].[dbo].[Sales_UnknownCustomer] AS T4_1 WHERE ([T4_1].[CustomerKey] = 0)) AS T3_1 INNER JOIN (SELECT … FROM (SELECT … FROM [sample_vsplit].[dbo].[SaleItems_UnknownCustomer] AS T5_1 WHERE ([T5_1].[CustomerKey] = 0)) AS T4_1 INNER JOIN (SELECT … FROM (SELECT … FROM [sample_vsplit].[dbo].[Delivery_SaleItems_UnknownCustomer] AS T6_1 WHERE ([T6_1].[CustomerKey] = 0)) AS T5_1 INNER JOIN (SELECT … FROM [sample_vsplit].[dbo].[Deliveries_UnknownCustomer] AS T6_1 WHERE ([T6_1].[CustomerKey] = 0)) AS T5_2 ON (([T5_2].[CustomerKey] = [T5_1].[CustomerKey]) AND ([T5_2].[SalesKey] = [T5_1].[SalesKey]) AND ([T5_2].[DeliveryKey] = [T5_1].[DeliveryKey]))) AS T4_2 ON (([T4_1].[CustomerKey] = [T4_2].[CustomerKey]) AND ([T4_1].[SalesKey] = [T4_2].[SalesKey]) AND ([T4_2].[SaleItemKey] = [T4_1].[SaleItemKey]))) AS T3_2 ON (([T3_2].[CustomerKey] = [T3_1].[CustomerKey]) AND ([T3_2].[SalesKey] = [T3_1].[SalesKey]))) AS T1_1 |
This may seem more complex – it’s certainly longer – but this is the original, preferred version of the join. This is a powerful rewrite of the query.
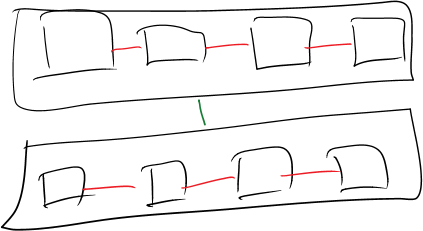
Furthermore, the astute PDW-familiar reader will quickly realise that the UNION ALL of two local queries (queries that don’t require data movement) is also local, and that therefore, this query is completely local. The TEMP_ID_NNNNN tables in the first rewrite are more evidence that data movement has been required.
When the two plans are shown using PDW’s EXPLAIN keyword, the significance is shown even clearer.
The first plan appears as following, and it is obvious that there is a large amount of data movement involved.
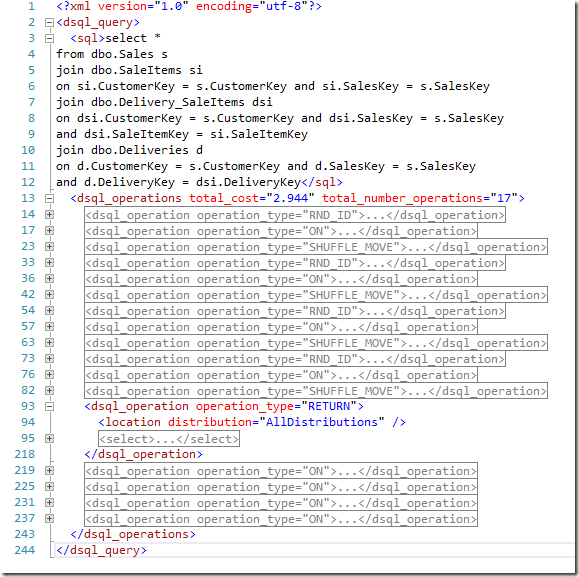

The queries passed in are identical, but the altered definitions of the views have removed the need for any data movement at all. This should allow your query to run a little faster. Ok, a lot faster.
Summary
When splitting distributed tables vertically to avoid skew, views over those tables should include predicates which reiterate the conditions that cause the data to be populated into each table. This provides additional information to the PDW Engine that can remove unnecessary data movement, resulting in much-improved performance, both for standard reports using designed queries, and ad hoc reports that use a data model.
Check us out at www.lobsterpot.com.au or talk to me via Twitter at @rob_farley




This Post Has 2 Comments
This is very interesting and I think has implications for Enterprise Edition where tables have been partitioned. I am working with a system currently where the only way to get SQL Server to do partition elimination is to generate queries very similar to the UNION ALL of small subqueries with predicates that align perfectly to the partition function.
I was reading the bit where you introduced contradictions, and then didn’t get how you actually used them in the query. I don’t think they are contradictions, they are more like obvious truths, or simulating constraints as you mentioned. "from KnownCustomer where customerID > 0" is not a contradiction, it is always true, right?
You’ve said:
"Before the predicates are used, the query on the views is rewritten as follows (with SELECT clauses replaced by ellipses)."
Do you mean that a person re-writes this or the query optimiser?
Also in the example following I don’t see any reference to the unknown_customer table. Am I missing something?
Then you said:
"Whereas with the inclusion of the additional predicates, the query simplifies to:"
Are you saying that having this view is good or bad?:
CREATE VIEW dbo.Sales AS
SELECT *
FROM dbo.Sales_KnownCustomer
WHERE CustomerID > 0
UNION ALL
SELECT *
FROM dbo.Sales_UnknownCustomer
WHERE CustomerID = 0;
If you join to this view with all of those associated tables is the query optimiser re-writing all of those queries to join the KnownCustomer related tables and then unioning all to the unknownCustomer joins?
Are you creating similar views for all of these associated tables and then just joining those views together naively and the query optimiser is doing the awesome no-move thing?
Why is the sky blue?
Hi Davos,
It’s the Query Optimizer that rewrites the queries.
In the example where you can’t see the ‘Unknown’ tables, it’s because there has been data movement, and that data is stored in the tempdb tables.
I’m saying the view is a good thing. It forces the extra predicates to be used, which contradict with each other on the joins that would require data movement. This means that the data movement doesn’t happen, and the query runs faster. 🙂
And yes – I’m creating similar views for Sales, SaleItems, Delivery_SaleItems and Deliveries, and then using the views "naively", and you put it.
And the sky is blue because other frequencies of light don’t scatter enough for us to be able to see them when the sun’s light hit various tiny particles in the atmosphere.
Rob